What Does It Cost to Maintain an AI Product After Launch?

Vasim Gujrati
Solutions Architect, AI & Platforms, Unico Connect
In this article
- Quick Answer
- Key Takeaways
- Why AI Maintenance Costs Are Different From Traditional Software
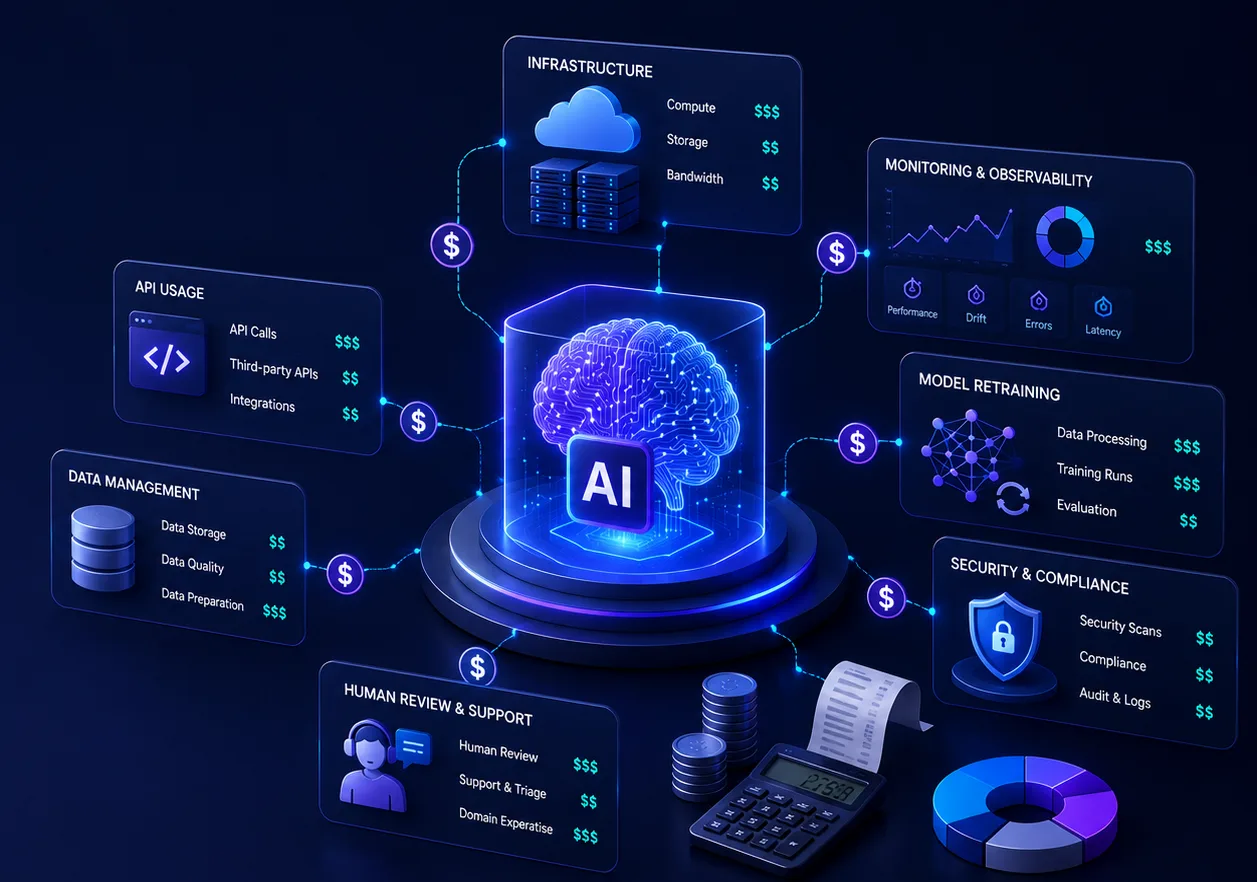
- What Actually Contributes to AI Product Maintenance Cost?
- AI Product Maintenance Cost Ranges by Product Type
- Infrastructure and Inference Costs Drive Long-Term AI Spend
- Monitoring, AI Evals, and Reliability Management
- How Better Engineering Decisions Reduce AI Maintenance Cost
- Frequently Asked Questions
AI product maintenance costs extend far beyond traditional cloud hosting, typically ranging from a few thousand to tens of thousands of dollars monthly. This ongoing operational discipline encompasses continuous monitoring, inference execution, governance, system scaling, and human oversight. Exact costs fluctuate heavily depending on AI complexity, inference volume, third-party integrations, and an organization's operational maturity. Maintaining AI systems requires treating post-launch operations as a dynamic optimization cycle rather than a static, one-time post-launch expense.
Quick Answer
Maintaining an AI product after launch typically runs from a few thousand to tens of thousands of dollars a month — about $500 for a simple internal chatbot up to $20,000+ for complex multi-agent enterprise systems. The spend is driven not by hosting but by inference/token usage, monitoring and evals, governance, scaling, and human-in-the-loop oversight — a continuous optimization cycle, not a one-time cost.
Key Takeaways
- AI maintenance is an ongoing optimization cycle, not a one-time post-launch expense.
- Because models are probabilistic, you pay continuously for monitoring, evals, and oversight that deterministic software never needs.
- The biggest budget surprises come from inference volatility — token usage can scale exponentially under a traffic spike while server cost scales linearly.
- Human-in-the-loop workflows (approvals, exception handling, compliance) often cost more than the software itself.
- Observability-first architecture plus optimizations like model routing and semantic caching materially cut long-term cost.
Why AI Maintenance Costs Are Different From Traditional Software
Traditional SaaS applications execute deterministic logic; if the code does not change, the output remains stable. In contrast, AI software maintenance deals with probabilistic systems. Deployed models exhibit unpredictable behaviors over time, such as unprompted hallucinations, retrieval variability in RAG pipelines, and prompt drift as underlying APIs update.
Consequently, maintaining AI-powered applications is never a static process. It requires continuous monitoring, rigorous operational oversight, and iterative prompt optimization. True AI product lifecycle management demands that teams constantly evaluate systems post-launch to ensure output quality does not degrade. For example, a deterministic billing service runs reliably with standard uptime checks. However, a production AI workflow handling document extraction requires active, continuous evaluation against baseline truth sets to ensure data drift hasn't skewed the core extraction logic.
This is not new to generative AI. Google's research on hidden technical debt in machine learning systems showed that only a small fraction of a real-world ML system is the model code itself — the surrounding infrastructure and ongoing maintenance dominate the total cost of ownership.
What Actually Contributes to AI Product Maintenance Cost?
The true cost to maintain AI applications fractures into several highly variable operational categories. The baseline consists of infrastructure hosting and API/inference usage, which directly scale with token limits and computational load. Beyond hosting, teams must budget for comprehensive monitoring and observability tools, security and compliance audits, prompt optimization cycles, and stringent governance management.
Post-launch AI maintenance costs compound aggressively as systems introduce multi-agent orchestration or process multimodal AI inputs. Additionally, AI operational expenses must account for human-in-the-loop workflows. Whether it is manual approval workflows, exception handling, or compliance reviews, these operational staffing requirements often eclipse software costs. As enterprise systems scale, governance becomes a primary cost driver to prevent data leakage and ensure model safety.
In our experience at Unico Connect, the most significant budgeting surprises stem from inference volatility and operational unpredictability. When a client application experiences a sudden traffic spike, standard server costs scale linearly, but unoptimized LLM token usage can scale exponentially. Managing AI product support and maintenance requires treating operational overhead as an equal mix of technical infrastructure and human administrative processes.
AI Product Maintenance Cost Ranges by Product Type
Estimating AI system maintenance cost requires evaluating the specific architectural profile. Operational costs fluctuate heavily based on traffic volume, backend integrations, compliance requirements, latency expectations, and workflow complexity.
| Product type | Relative monthly cost | Primary cost drivers |
|---|---|---|
| Internal chatbot / wiki assistant | Lowest (from ~$500) | Inference volume, light monitoring |
| Customer-facing RAG application | Moderate | Retrieval infrastructure, evals, higher traffic |
| Regulated-industry RAG (e.g. healthcare) | High | Compliance and governance overhead |
| Multi-agent / multimodal enterprise system | Highest (to $20,000+) | Orchestration, GPU, human-in-the-loop |
Even within the same tier, AI application maintenance services differ drastically. Two RAG applications might look identical, but one operating in a regulated healthcare environment will incur massive compliance and governance overhead, pushing its AI infrastructure cost far higher than an internal company wiki assistant. Enterprise AI systems demand dedicated operational workflows that fundamentally shift the pricing baseline.
Infrastructure and Inference Costs Drive Long-Term AI Spend
At the core of long-term AI spend are token-based pricing structures and persistent inference costs. Scaling economics in AI are fundamentally different from traditional computing. AI infrastructure cost encompasses not just the LLM execution, but also the supporting architecture: persistent vector databases, retrieval infrastructure, heavy logging pipelines, and orchestration layers.
Engineering teams face a continuous choice between relying on managed API-based model usage (which incurs variable token costs) versus self-hosted open-source models (which demand expensive, fixed cloud GPU expenses). Optimization decisions here directly impact the bottom line. Intelligent model routing (sending simple queries to smaller, cheaper models), semantic caching strategies, aggressive prompt optimization, and balancing latency-cost tradeoffs can significantly slash LLM operational cost. Balancing peak performance with operational efficiency is an active engineering task, not a set-and-forget configuration — the same discipline we cover in AI development workflows.
Monitoring, AI Evals, and Reliability Management
Because probabilistic models generate dynamic responses, deployed systems require continuous, rigorous monitoring. Standard uptime pings are insufficient. AI software maintenance requires actively tracking hallucination detection, evaluating retrieval quality, catching prompt drift, and ensuring overall response consistency.
Consequently, implementing automated AI evals is a strict operational necessity, not an optional optimization layer. A reliable AI monitoring and observability stack incorporates continuous production testing, reliability scoring, and mandatory human review checkpoints for low-confidence outputs. For example, in our internal QA workflows, we routinely route random samples of generated responses through a secondary "evaluator" LLM to score factual alignment against source documents. By catching logic degradation early, proactive monitoring drastically reduces long-term operational instability and controls runaway AI model monitoring costs before it impacts end users.
How Better Engineering Decisions Reduce AI Maintenance Cost
High AI maintenance costs are often a symptom of poor initial architecture. Intentional engineering decisions directly improve maintainability. Building modular systems with an observability-first architecture allows teams to isolate failing components quickly. Implementing aggressive semantic caching strategies, dynamic model routing, and strict workflow isolation minimizes unnecessary compute cycles.
These AI-native engineering practices reduce operational inefficiencies, prevent infrastructure waste, and simplify monitoring complexity. From a deployment maturity perspective, teams attempting to bolt monitoring onto an application post-launch face substantially higher technical debt than teams that architected for observability from day one. Sustainable post-launch AI maintenance requires active operational planning rather than reactive cost management — closely related to the discipline of keeping AI code maintainable at scale.
AI maintenance budget checklist:
- Infrastructure forecasting: estimate token volume and vector storage scaling assumptions over a 12-month period.
- Monitoring stack planning: budget for specialized LLM observability and evaluation platforms.
- Human review workflows: allocate dedicated personnel for exception handling, compliance, and QA.
- Compliance planning: ensure ongoing data privacy audits and security updates are factored into sprint cycles.
- Scaling assumptions: map out exactly how API rate limits and inference costs behave during unexpected traffic spikes.
Frequently Asked Questions
How much does AI product maintenance cost per month?
AI product maintenance costs typically range from $500 for simple internal chatbots to over $20,000 for complex, multi-agent enterprise systems. Exact costs vary heavily based on infrastructure choices, inference volume, workflow complexity, and specialized monitoring requirements.
Why are AI operational expenses higher than traditional software maintenance?
Unlike deterministic software, AI systems generate probabilistic outputs. This requires AI software maintenance to include continuous monitoring, automated model evaluation, hallucination detection, and ongoing operational oversight to prevent response drift.
What increases the cost to maintain AI applications at scale?
The cost to maintain AI applications scales aggressively when introducing complex multi-agent workflows, higher traffic volumes, strict governance complexity, and the expanding infrastructure scaling required to process heavy multimodal inputs.
Does AI monitoring and observability reduce long-term operational risk?
Yes, reliable AI monitoring and observability allow for early issue detection, accurate reliability management, and clear operational visibility. This ensures workflow stability by catching prompt drift and logic degradation before they affect end users.
What is included in AI application maintenance services?
Comprehensive AI application maintenance services include continuous model monitoring, infrastructure management, prompt optimization, data governance enforcement, and staffing for human-in-the-loop support workflows. Our AI development team runs this end to end.



