Built document intelligence systems that turn unstructured documents into structured knowledge with high-accuracy extraction and grounded, retrieval-augmented answers
A capability case covering the document intelligence systems Unico Connect has built across client engagements, combining structured extraction from unstructured documents, retrieval-augmented generation against grounded knowledge bases and conversational answers that respect the source material.
Key Takeaways
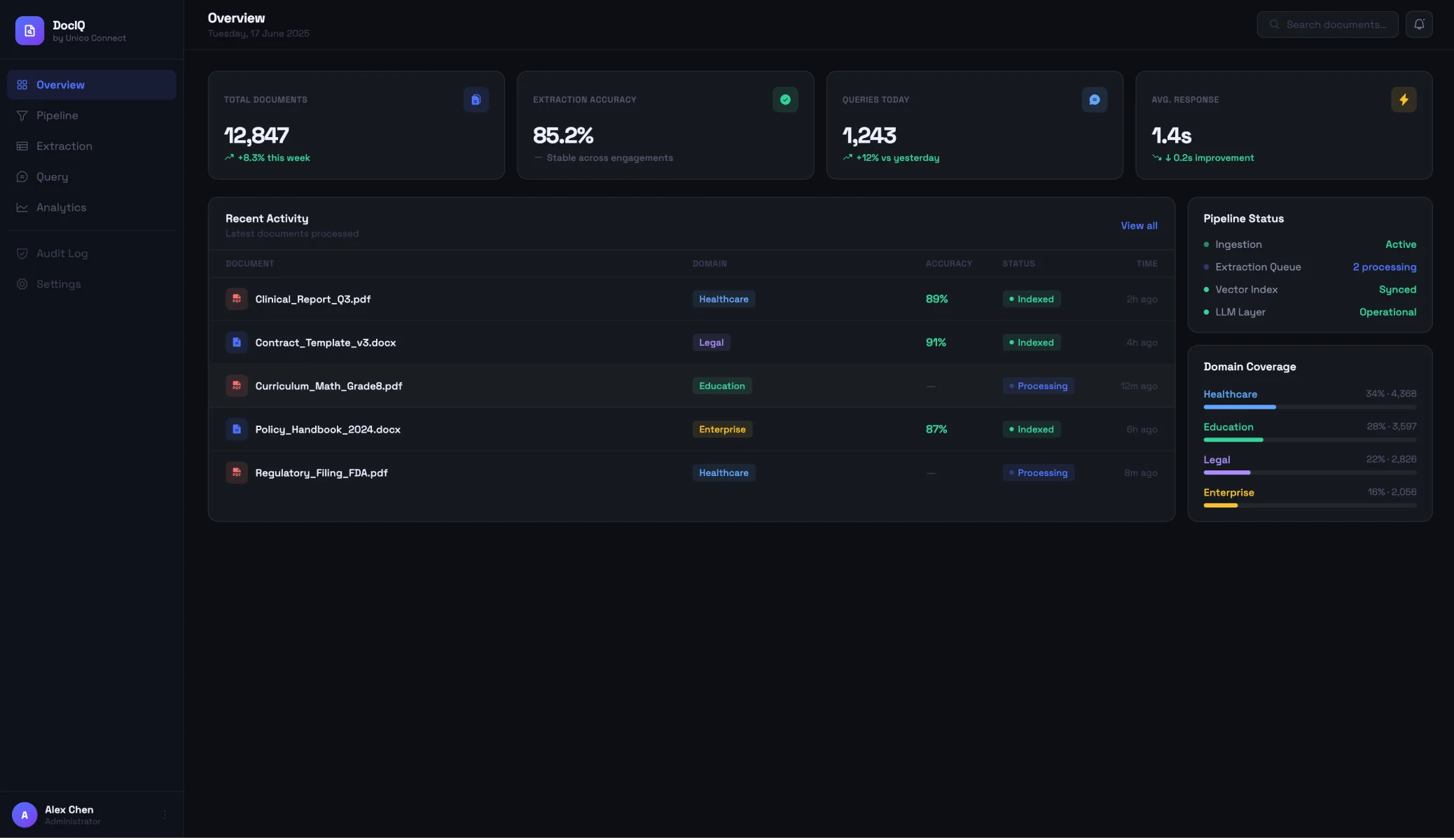
Document intelligence is the AI capability that turns the documents an organisation already holds into systems people can actually use. Unico Connect has built this capability across client engagements covering structured data extraction from unstructured documents, retrieval-augmented generation against grounded knowledge bases, and conversational answers that respect the source material rather than generating freely.
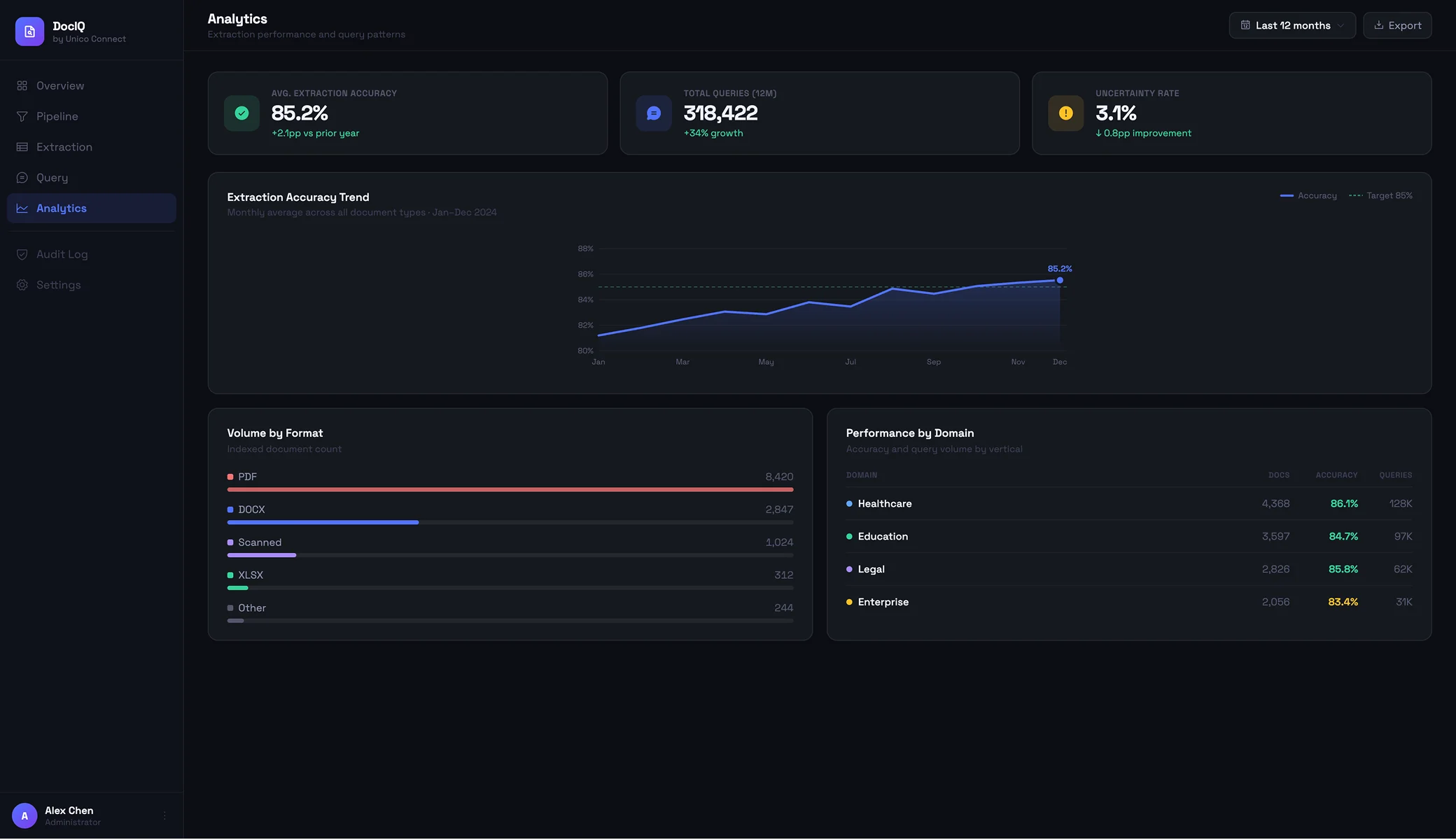
The work consistently delivers strong extraction accuracy, around 85 percent when tuned to the client corpus, with the kind of audit posture that regulated and high-trust contexts require. The combination of extraction and grounded retrieval is what produces document intelligence systems that organisations trust enough to actually adopt.

The Challenge
Most organisations sit on a body of documents they cannot fully use. Policies, contracts, technical documentation, product manuals, research material, regulatory filings and training content all exist, they are valuable, but they are not in a form that lets the organisation extract their value at scale. Finding the right answer in a large document corpus is slow. Extracting structured data from unstructured documents is error-prone. Building conversational interfaces over the corpus introduces hallucination risk that most organisations cannot tolerate.
The pattern that surfaced across our client engagements was consistent. A client has a document corpus that matters. The corpus is varied across formats, sources, structures and vintages. The use cases are similar: ask questions of the corpus and get accurate answers grounded in the documents, extract specific structured data from unstructured documents at scale, or both. The standard approaches fail for predictable reasons. Generic LLMs hallucinate. Document parsing tools produce extraction with too low an accuracy rate to trust. Search tools surface relevant documents but do not synthesise the answer.
The opportunity was to solve this pattern properly. The capability we have built across engagements combines structured extraction, turning the unstructured into the structured with the accuracy that downstream workflows actually require, with retrieval-augmented generation, turning the question into an answer with the grounding that prevents hallucination. The engagements have spanned categories with very different requirements: education teams needed conversational answers over curriculum materials they could trust, healthcare teams needed structured extraction from clinical and operational documents with an audit trail, legal teams needed precise retrieval over policy and case documents, and enterprise teams needed knowledge bases over policies and product documentation that employees could actually query.
The common thread is that document intelligence is not one capability; it is a pattern of capabilities that have to work together. Extraction without retrieval is incomplete. Retrieval without extraction is shallow. Conversational answers without grounding are dangerous. Building all three together with the right architectural discipline is the work.
Our Approach

The approach we have developed across client engagements is built around three integrated layers, each tuned to the specific requirements of the engagement: an ingestion and extraction layer, a retrieval and indexing layer, and a conversational answer layer. Throughout, we treat the audit posture as a first-class concern rather than an afterthought.
Key decisions:
Extraction tuned to the corpus, not generic
The ingestion pipeline absorbs the formats clients actually use, PDFs, Word documents, scanned imagery and structured data exports, and runs them through extraction logic specialised to the document type. For tabular data it targets the structured fields; for prose it targets the semantic structure the downstream use cases need. Accuracy stays strong, around 85 percent, because the extraction is tuned to the client corpus rather than applied generically.
Retrieval that respects how each domain searches
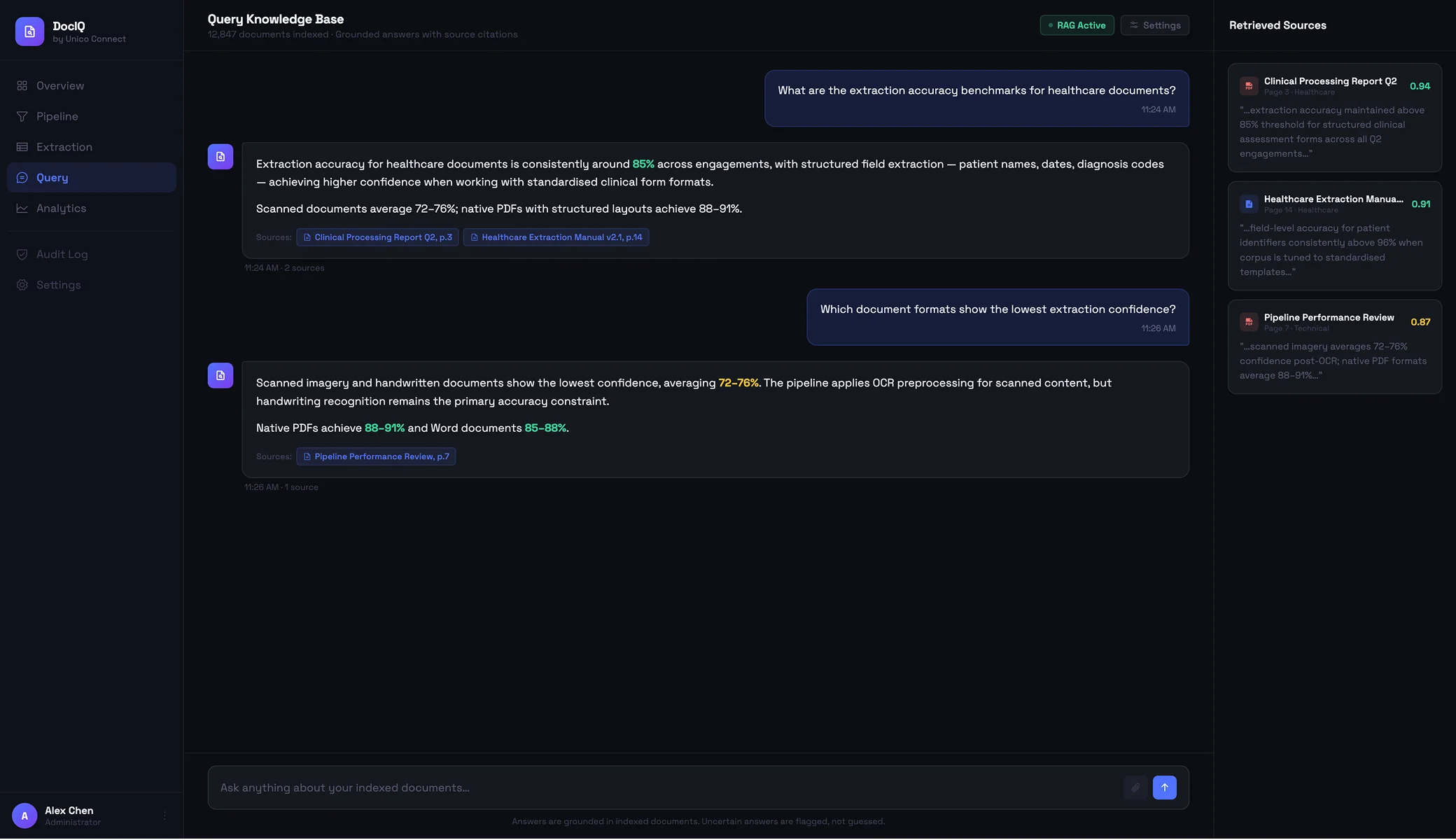
The retrieval layer turns the extracted content into a knowledge base the conversational layer can query, using retrieval-augmented generation patterns that ground the model in the source material rather than letting it generate freely. The indexes are designed for the way users actually search: a legal user by case and clause, a clinical user by condition and procedure, a teacher by topic and curriculum point.
Grounded answers, validated, with an audit posture
Answers draw from the source material and surface the supporting references so a user can verify or dive deeper. When the corpus does not contain the answer, the question is ambiguous, or the retrieval surfaces conflicting material, the system signals that uncertainty rather than producing a confident wrong answer. For regulated contexts, every answer can be traced back to the source documents.
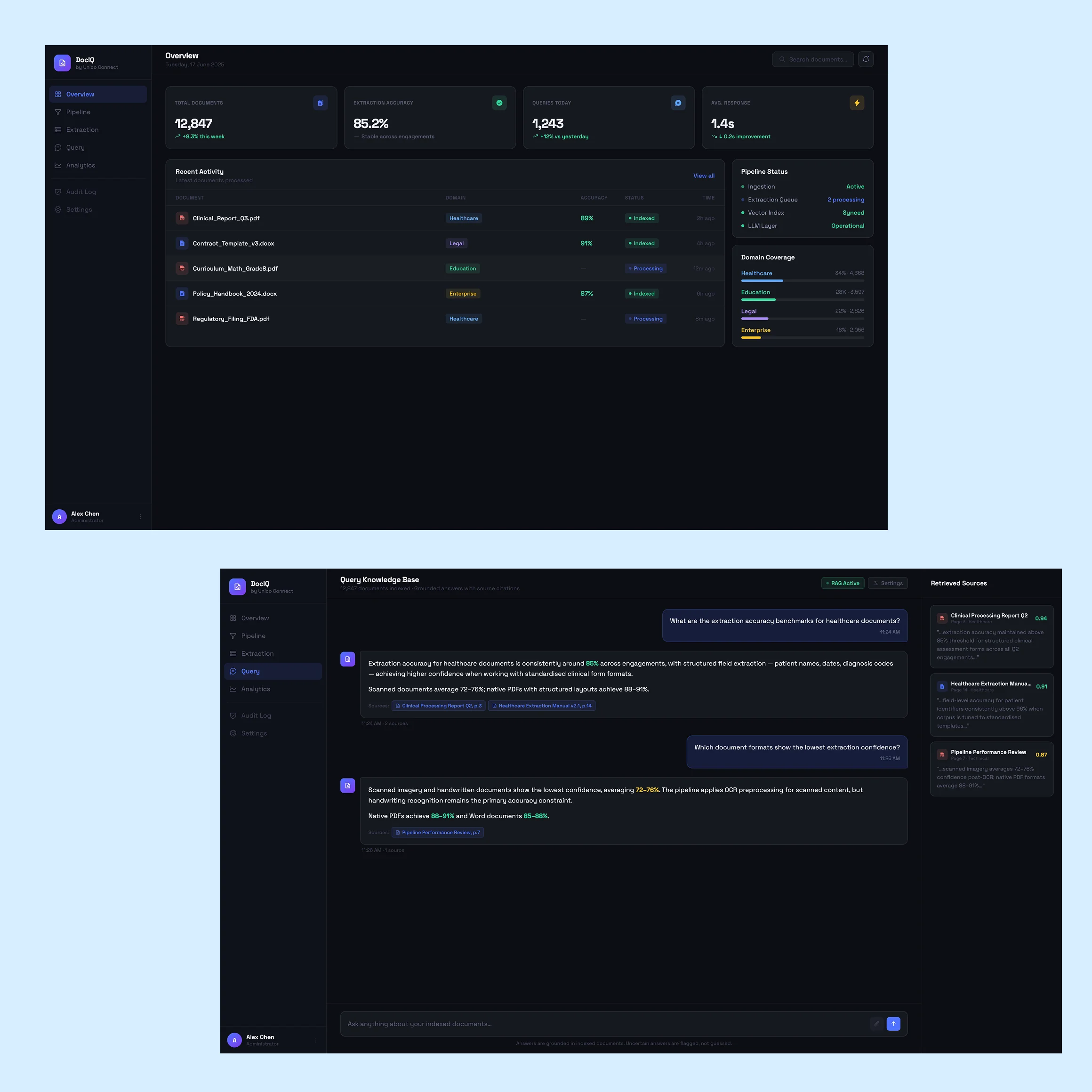
The solution we built
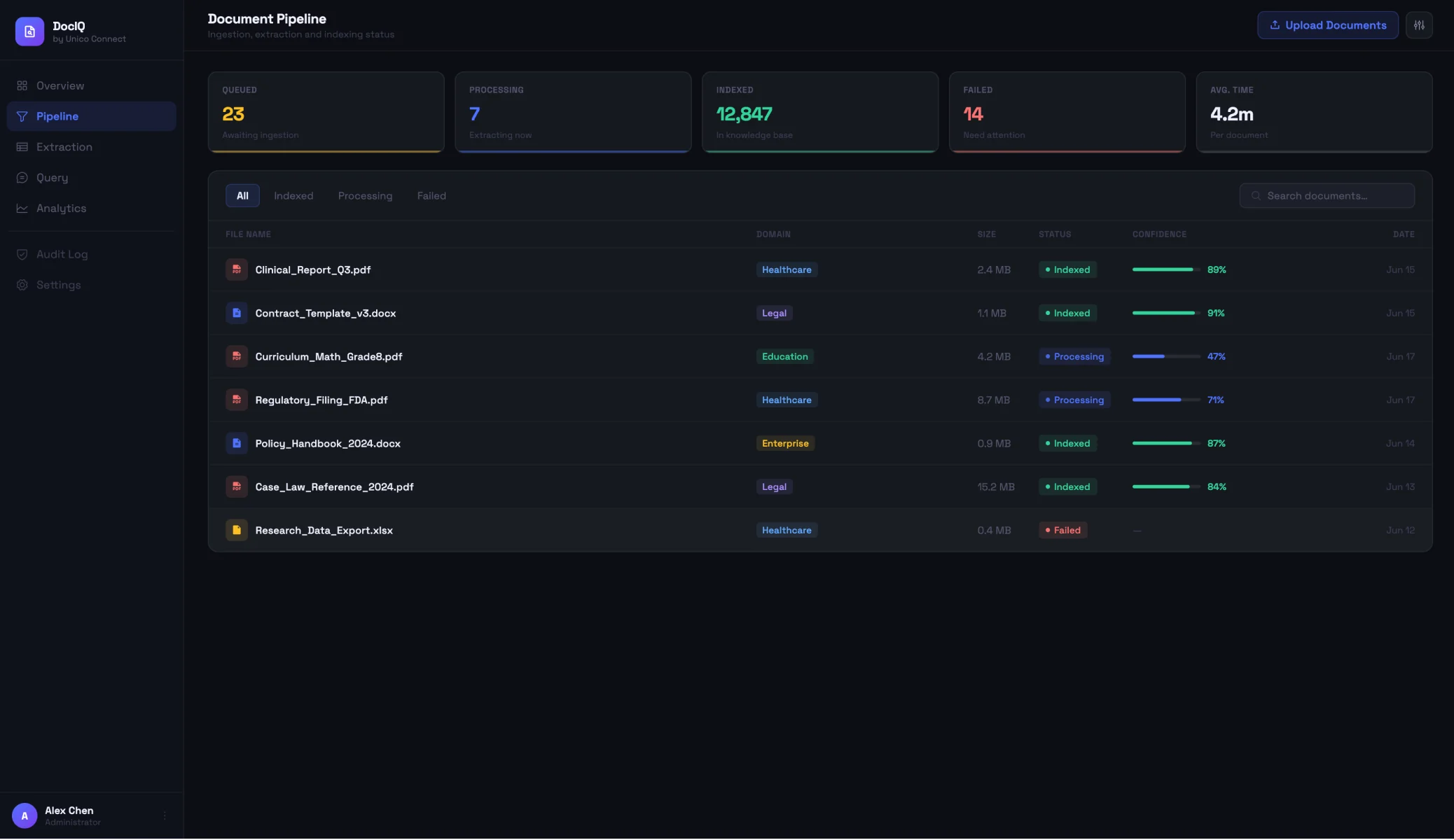
The capability we deliver across engagements is structured around three layers, with each engagement tuning the specifics to the client context. New documents are ingested in batch for existing corpora or continuously for live document feeds, the pipeline normalises formats, runs the extraction, and stores the structured output alongside the source material.
Document ingestion pipeline
Handles the document formats and inflows the client actually has. The pipeline normalises PDFs, Word documents, scanned imagery and structured data exports, then routes each document into the extraction logic specialised to its type. New formats are supported by extending the pipeline rather than rebuilding it.
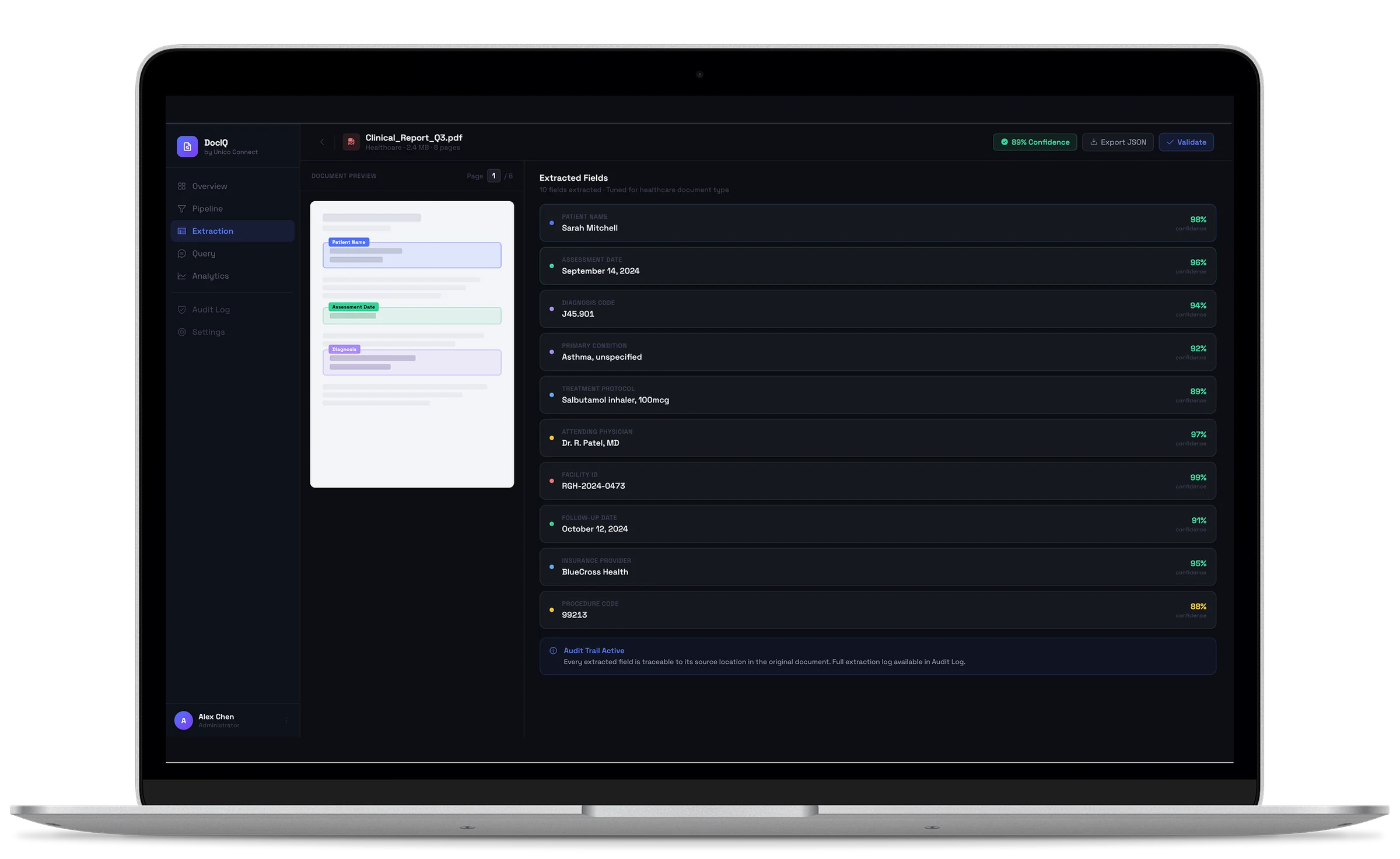
Structured extraction layer
Extraction logic specialised by document type and engagement: regulatory tables from healthcare documents, contract terms from legal documents, curriculum points from educational material. Each field is extracted with a confidence score, and accuracy of around 85 percent is held across contexts by tuning the extraction rather than applying it generically.
Retrieval and indexing
Vector indexing for semantic retrieval combined with keyword indexing for terminology that requires exact match. The indexing strategy is designed for the way users in the specific domain actually query, so retrieval reflects real search patterns rather than producing generic semantic search.
Retrieval-augmented generation
Combines the retrieved material with the model generation, with the prompting structure and grounding constraints that keep the model inside the source material. When the corpus contains the answer the system provides it; when it does not, the system says so rather than guessing.
Conversational answer surface
The user-facing layer. Users ask questions in natural language and answers come back drawing on the source material with the supporting references surfaced. Answers read naturally but stay anchored in the documents, and uncertainty is signalled rather than hidden.
Audit and traceability
Every answer and extracted field can be traced back to the source documents. For regulated contexts the audit trail is built into the system; for high-trust contexts the behaviour is predictable and explicable. This is what makes the capability deployable in production rather than impressive only in a demo.
Tech stack






Outcomes & Impact
Extraction accuracy
Strong extraction accuracy, around 85 percent, tuned per corpus
Accuracy is held in the high range across engagements when the extraction is tuned to the client document corpus rather than applied generically. That consistency is what lets clients trust extracted data enough to move work off manual processing.
Grounded answering
Source-referenced answers that signal uncertainty rather than guessing
The grounded retrieval is the structural feature that makes the capability deployable in high-trust contexts. None of these settings tolerate a confident wrong answer, and the grounding discipline is what makes the system usable in front of teachers, clinicians, lawyers and employees.
Operational shift
Manual document work shifts to AI-assisted workflows
Knowledge retrieval that previously required expert assembly now happens through the conversational layer, and compliance and audit work that previously required manual reconstruction now operates against the system audit trail.
Reusable capability
A repeatable capability across document-heavy operations
The architectural patterns are reusable across engagements, the accuracy and grounding thresholds are predictable, and the deployment patterns repeat. The capability has become a structural part of how Unico Connect approaches AI work for clients with document-heavy operations.
Trusted and verified by our clients
Frequently Asked Questions



Tell us about your project
Tell us about your document corpus, the use cases that matter and where you want the capability to be in twelve months. A 30-minute call is the fastest way to find out whether Unico Connect is the right partner.
Prefer to book directly?
🗓️ Schedule on Calendly →Or email us:
✉️sales@unicoconnect.com