Built an intelligent PHI detection and redaction platform for DICOM medical imaging that preserves diagnostic quality while removing patient identifiers
An AI-powered platform that automatically identifies and redacts protected health information from DICOM files — including burned-in text and metadata that standard anonymisation tools miss — with regulatory compliance and diagnostic image quality both preserved.
Key Takeaways
A healthcare technology provider working with medical imaging data came to Unico Connect to solve a problem standard anonymisation tools could not. DICOM files carry protected health information in burned-in text, image regions and metadata, and existing tools missed enough of it to make automated workflows unsafe.
We built an intelligent PHI detection and redaction platform that handles each of those PHI surfaces automatically while preserving the diagnostic information clinicians need — removing manual redaction effort and reducing compliance risk.

The Challenge
Medical imaging operates under a strict regulatory boundary. Patient data — from a name embedded in a DICOM header to a date of birth burned into an X-ray corner — must be removed before images can be shared, used for research, or fed into downstream AI training pipelines. The boundary is not negotiable, and the penalty for getting it wrong is significant. The problem is that doing it correctly, at scale, is much harder than it looks.
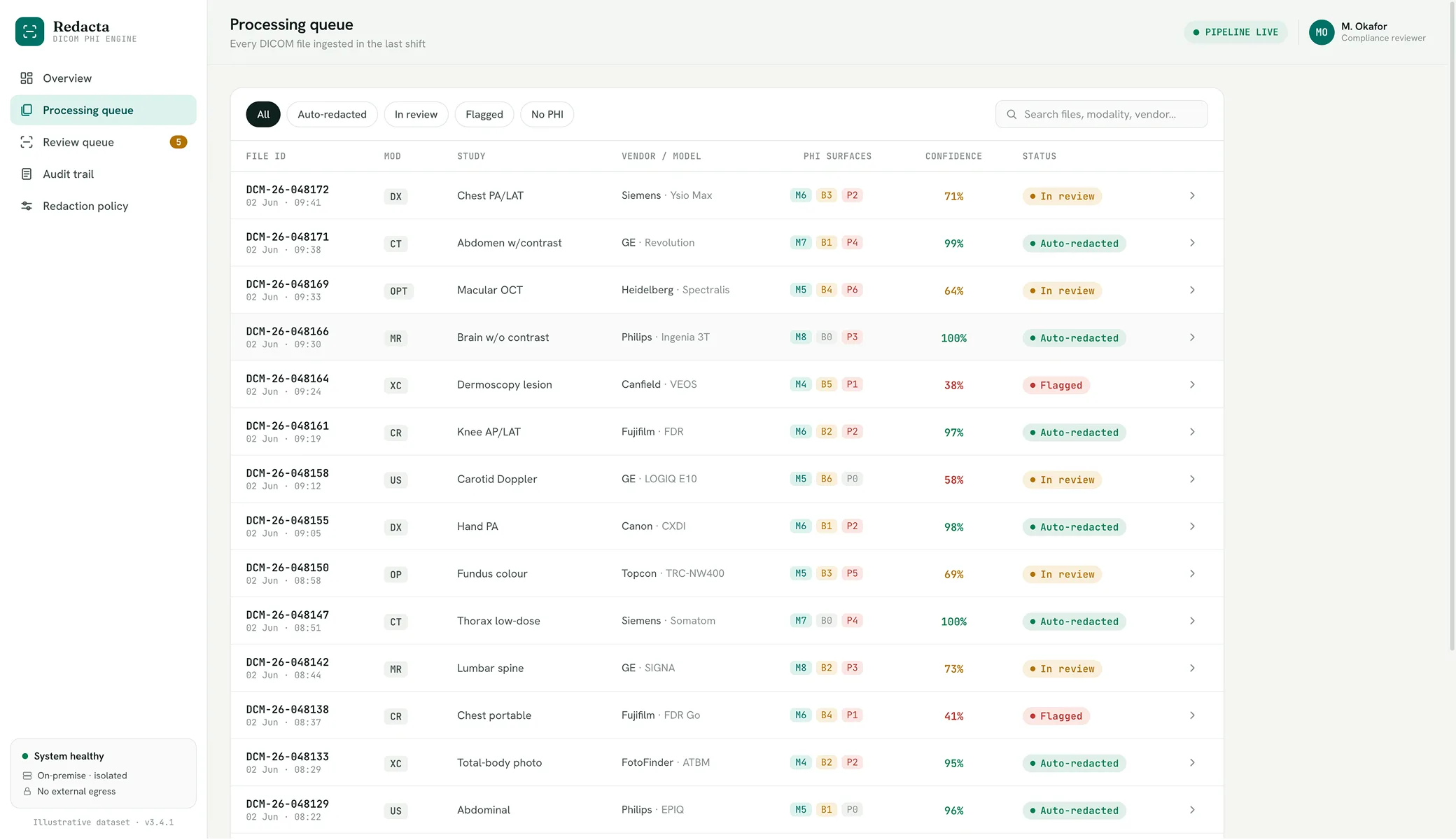
Standard anonymisation tools handle DICOM metadata reasonably well — the structured fields where patient name, ID and dates live. What they tend to miss is everything else: identifiers burned into the image itself as machine overlays or clinician annotations, text in image regions that looks like imagery, and identifiers in private DICOM tags that vary by manufacturer. The manual workaround — someone reviewing each file and redacting what the tool missed — is time-consuming, error-prone and impossible to scale.
What made the engagement interesting was that the problem was not one technique applied well. It was several techniques — computer vision for burned-in text detection, structured anonymisation for metadata, vendor-specific handling for private tags — working together with the right thresholds and the right human override paths. The client had explored building this in-house and decided the work was specialised enough to warrant a dedicated engineering partner.
Our Approach

We took the engagement on as a focused engineering build, with the team structured to combine machine learning depth with medical imaging domain experience. The first phase was understanding the actual PHI surfaces the client’s customers were dealing with, which varied across imaging modalities and manufacturers. We surveyed the real file set rather than the documented one, because the documented one rarely tells the whole story.
Key decisions:
Three layers for three PHI surfaces
Structured anonymisation for metadata and private vendor tags, a computer-vision pipeline for burned-in text, and a human-in-the-loop path for ambiguous annotations.
Diagnostic quality as a hard constraint
The CV pipeline is conservative around regions carrying diagnostic information, biased toward referring to a human reviewer rather than making a destructive automatic edit.
Network-isolated deployment
The platform runs within the customer’s network against their storage — medical imaging data never leaves their environment, which cloud-only tools cannot offer.
The solution we built
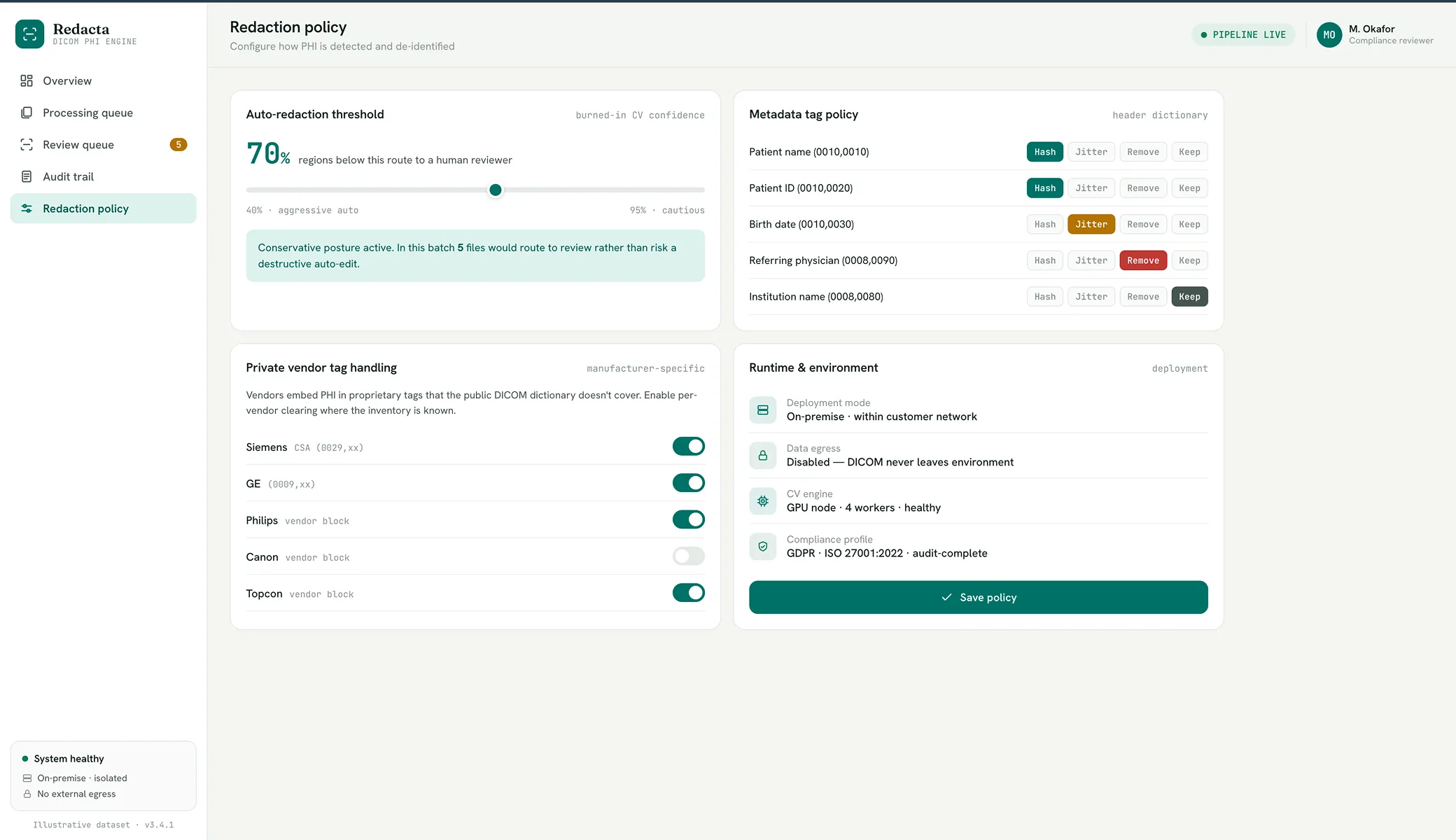
The platform processes DICOM files end-to-end across three integrated workflows, with the imaging data never leaving the customer’s environment and a complete decision record captured for every file.
Metadata anonymisation
Standard anonymisation against the public DICOM tag dictionary plus configurable handling of private vendor-specific tags, tightened against the real private-tag inventory.
Computer-vision redaction
Scans each image for burned-in text, classifies it as PHI or diagnostic content using position, format and context, and redacts identifiers while leaving diagnostics untouched.
Human-in-the-loop review
When the classifier is uncertain, the file is routed to a reviewer rather than redacted automatically — the safeguard that keeps diagnostic content safe.
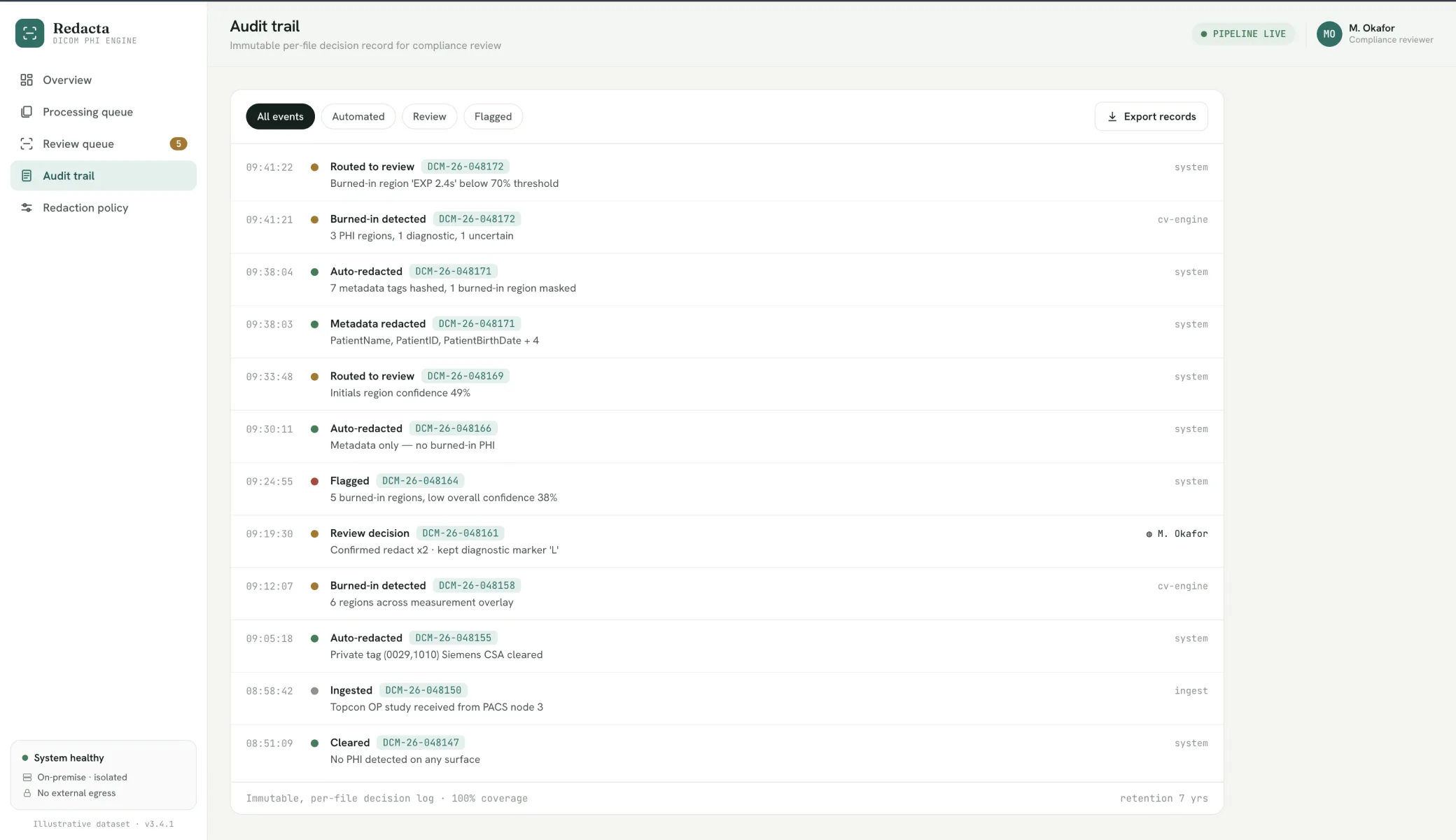
Audit trail and in-network deployment
A per-file record of what was detected, redacted, reviewed and decided, in a unit that deploys inside the customer network with operational interfaces for their teams.
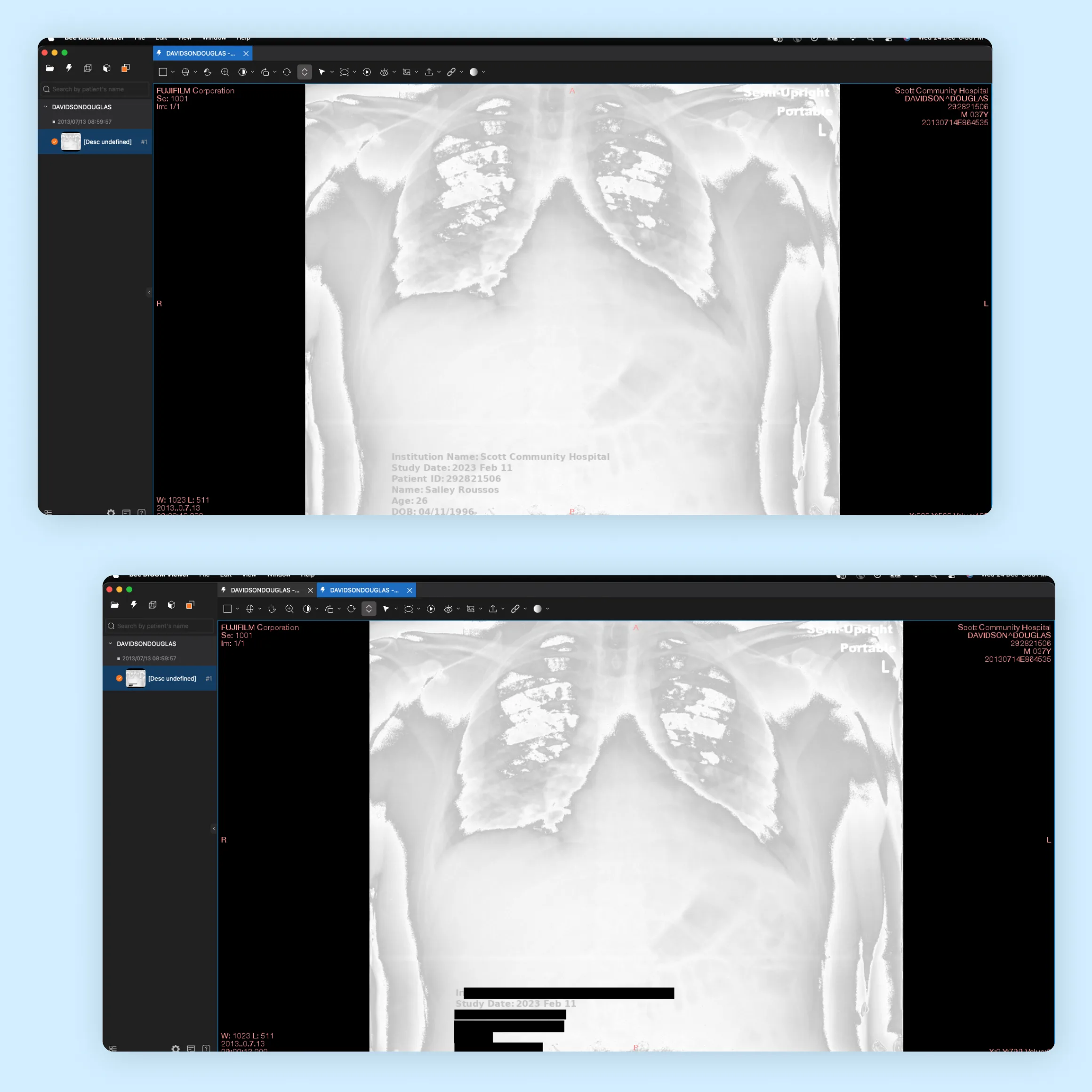
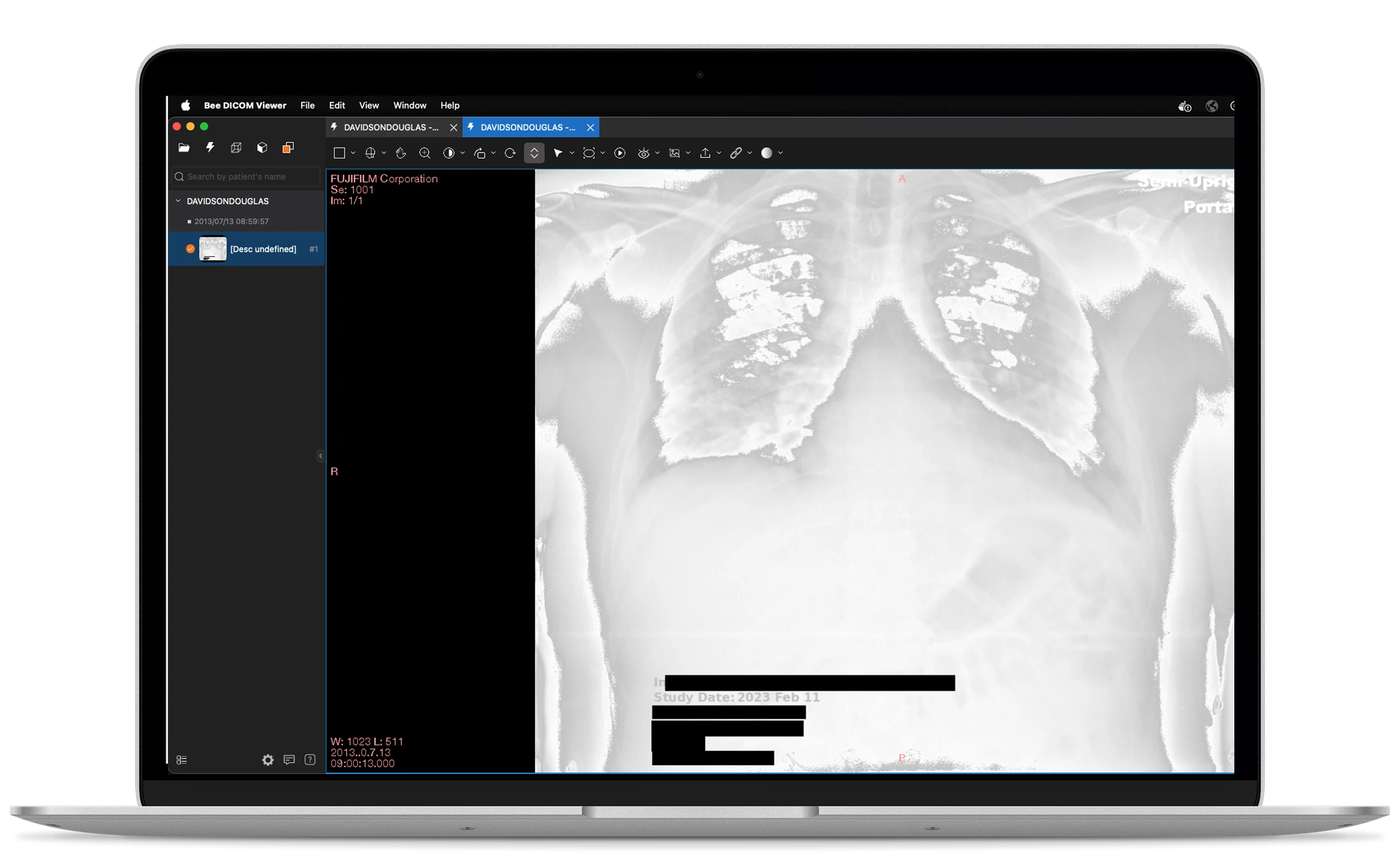
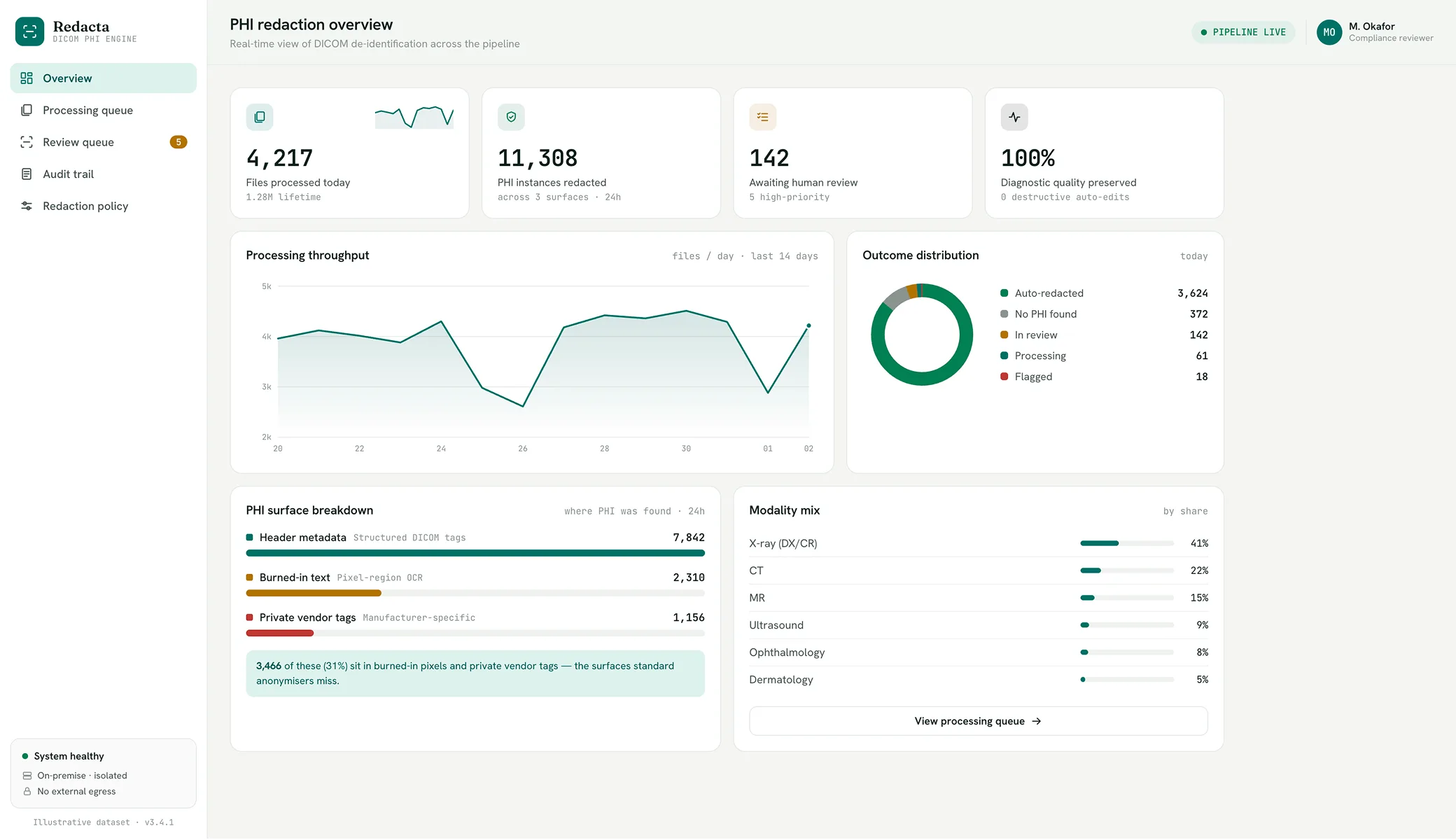
Outcomes & impact
Compliant
Complete per-file audit trail, defensible in a compliance review
Preserved
Diagnostic image quality across processed files
In-network
Deploys within the customer network; imaging data never leaves
Trusted and verified by our clients
Frequently Asked Questions
Related insights
View All


Let's Build Your Team
Tell us about your data, the compliance constraints you operate under and where you want the platform to be in twelve months. We'll get back within one business day with a plan and next steps.
Prefer to book directly?
🗓️ Schedule on Calendly →Or email us:
✉️sales@unicoconnect.com