Quick answer
A generative AI development company builds production systems on top of foundation models such as GPT-5, Claude Fable 5, Gemini 2.5, and Llama 4, extended with retrieval augmented generation (RAG), fine tuning on domain data, multimodal inputs, and agentic workflows. Unico Connect ships generative AI features across fintech, healthcare, education, and SaaS in 13+ countries. Every project includes evaluation pipelines, cost controls, and human-in-the-loop guardrails so production AI keeps performing after launch, not just in the demo.



From Demo to Production — How We Build Generative AI Differently
Most generative AI projects look impressive in the demo and fall apart in production. We've built a delivery model that closes that gap — evaluations, guardrails, and operational maturity from day one.
Typical GenAI Project
Single prompt engineered in a notebook
A working prototype on cherry-picked examples that breaks on real production inputs and edge cases.
No evaluation harness
Changes to prompts or models are tested by hand, which means regressions ship silently and accuracy drifts unnoticed.
Generic foundation model, no retrieval
Hallucinations on domain-specific questions because the model has no grounding in your actual product, documentation, or data.
Cost runs away after launch
Token spend balloons as usage grows because there is no budget per request, no caching, and no multi-model routing.
No fallback when the model fails
When inference is slow, rate-limited, or wrong, the user-facing experience just breaks — no graceful degradation, no human handoff.
Production-Grade GenAI (How We Build)
Versioned prompts in source control
Every prompt is a tracked artefact with a changelog, A/B tested before promotion. Rollbacks take seconds, not days.
Evaluation pipelines with golden test sets
LangSmith / Promptfoo / custom evals run on every change. We catch regressions and accuracy drift before users do.
RAG grounded in your data
Domain answers come from your documents, not the model's training set. Citations are surfaced so users (and reviewers) can verify.
Cost controls and multi-model routing
Cheap models handle easy queries; premium models handle hard ones. Per-request budgets and caching keep token cost predictable.
Guardrails, fallbacks, and human-in-the-loop
Confidence thresholds, content filters, and escalation paths to human reviewers — AI never makes irreversible decisions alone.
Generative AI Capabilities
LLM-Powered Chatbots & Copilots
Production chatbots, support copilots, and embedded assistants. Memory, tool use, retrieval, and graceful fallback architecture — built for daily use, not demo screenshots.
RAG & Knowledge Retrieval
Document ingestion, chunking, embeddings, vector indexing (Pinecone, Weaviate, pgvector), and reranking. Production-grade retrieval that scales beyond the proof of concept.
Fine-Tuning & Custom Models
Fine-tune open-source models (Llama 4, Mistral, Qwen) for cost reduction, domain adaptation, or IP control. Closed-model fine-tuning where supported.
Multimodal AI — Vision, Text, Audio
Vision-language (GPT-5, Claude Fable 5, Gemini 2.5), text-to-image (Imagen, FLUX, Stable Diffusion), and speech (Whisper, ElevenLabs). Combined for richer product experiences.
Content Generation — Text, Image, Code
Generative AI features inside real products: long-form drafts, image generation, code completion, document summarisation. Quality controls and edit suggestions baked in.
Agentic Workflows with Tool Use
Production agents using LangGraph, OpenAI Agents SDK, and Anthropic tool use. Multi-step plans, MCP servers, and human-in-the-loop checkpoints for high-stakes actions.
Technology Stack



























Our Work
Built an AI-powered learning platform with a retrieval-augmented tutor
25,000+
Members reached
+15%
Learner engagement
40%
More efficient than print
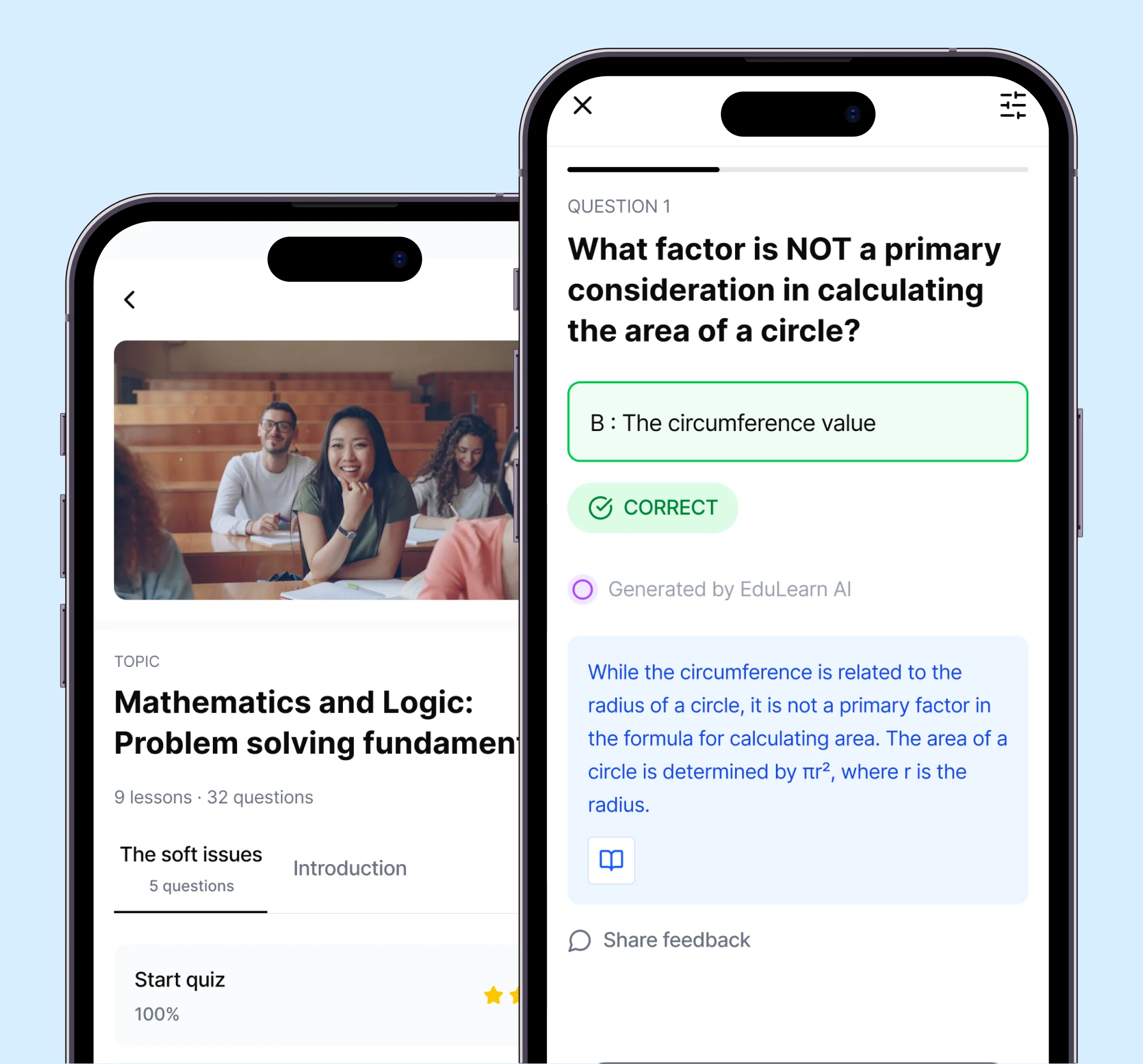
Built an AI-powered digital learning platform for one of California's largest charter schools
97%
AI grading accuracy
50%
Faster turnaround
15K+
Students served

Shipped an AI chat platform with text and voice for a consumer wellness brand
Text + Voice
AI conversation
5 domains
Profiling coverage
iOS + Android
Live mobile app
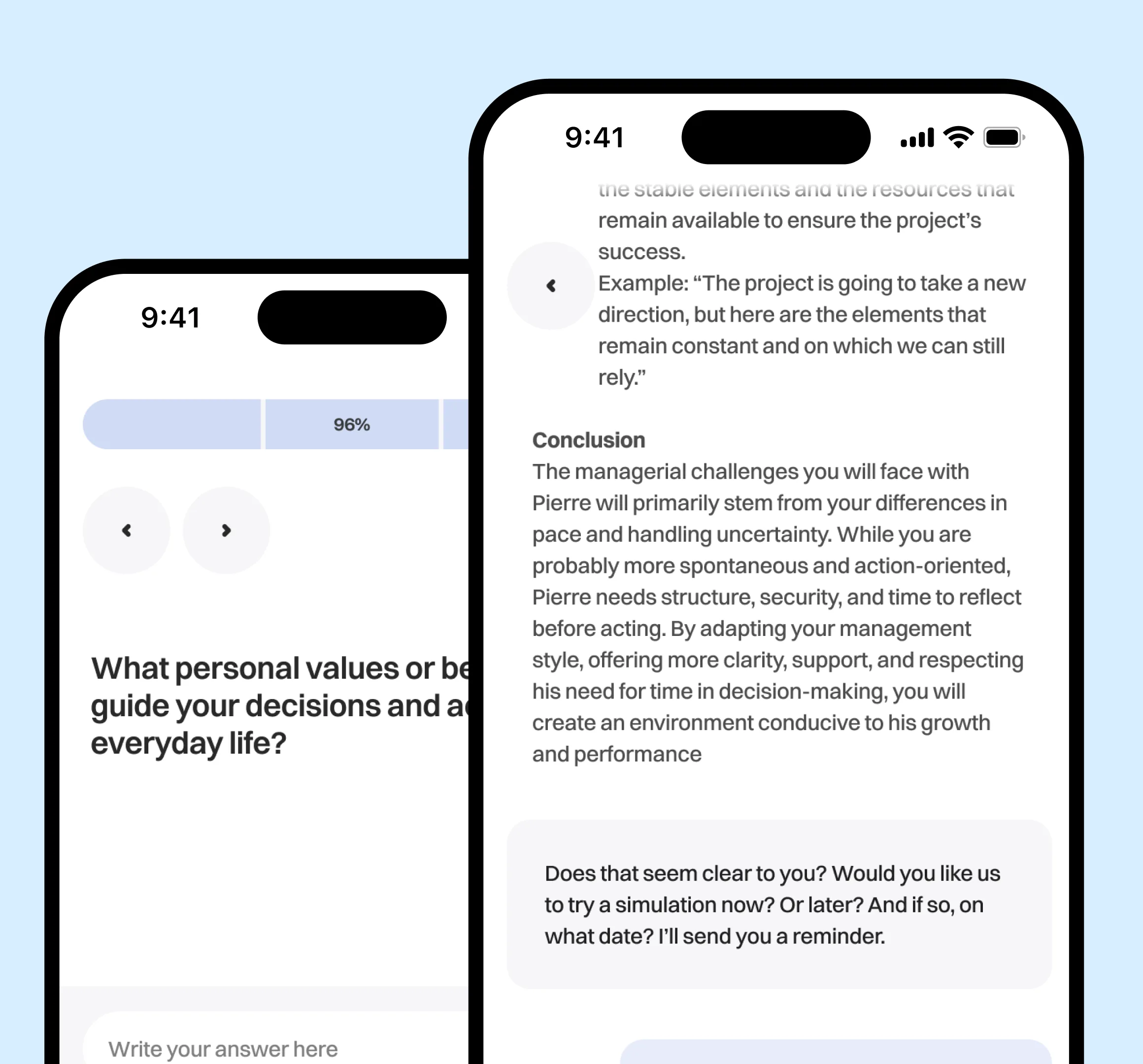
AI-powered e-commerce intelligence platform with generative insights and content
40%
Faster insights
25%
Revenue uplift
3×
Data processing speed

What Does a Generative AI Development Company Do
A generative AI development company designs, builds, and operates LLM powered software for other businesses. That covers scoping the use case, choosing and integrating foundation models, building RAG pipelines over your data, fine tuning where it pays, wiring guardrails and evaluation harnesses, and running the system in production with cost and quality monitoring. The difference between a generative AI development company and a general software agency is the production discipline around models. Prompts change behavior the way code does, model versions shift under you, and output quality has to be measured continuously rather than assumed.
The market context explains the demand. Worldwide AI spending is forecast to reach about $2.59 trillion in 2026, up 47% year over year, according to Gartner. Roughly 88% of organizations now use AI in at least one business function per McKinsey, yet MIT Project NANDA found that 95% of generative AI deployments show no measurable P&L impact. The gap between adoption and value is exactly what a production focused partner exists to close.
Generative AI Use Cases by Industry
The pattern that works is narrow and deep. One workflow, grounded in your data, measured against a baseline. These are shipped examples from our own delivery record.
- Education. The Highlands learning platform uses a RAG grounded tutor and LLM based grading at 97% accuracy, serving 15,000+ students with 50% faster content turnaround.
- Professional learning. A Swiss learning platform with a retrieval augmented tutor reached 25,000+ members and lifted engagement 15%.
- Ecommerce. EComm Pulse generates listing copy and weekly AI written competitor briefs, contributing to a 25% revenue uplift and 40% faster insights.
- Consumer wellness. An AI chat platform with text and voice conversation live on iOS and Android.
- Healthcare. DICOM PHI detection applies AI to medical imaging privacy, and AI document intelligence automates extraction from unstructured documents.
How Much Does Generative AI Development Cost
At our published estimate ranges, an AI pilot or MVP costs $15,000 to $50,000 and ships in 4 to 10 weeks. A production system with an evaluation harness, guardrails, and 3 to 5 integrations costs $50,000 to $150,000 over 2 to 6 months. Enterprise and multi agent platforms run $150,000 to $300,000 and up. Plan for running costs of 15 to 25% of the build cost per year to cover tokens, vector databases, hosting, and monitoring. The model is rarely the cost driver. Data preparation, integrations, and evaluation infrastructure consume most of the budget. The AI development cost guide has the full breakdown with a calculator.
RAG, Fine Tuning, or Prompt Engineering, Which Approach Fits
Start with prompt engineering, add RAG when answers must be grounded in your own data, and fine tune only when behavior, format, or cost targets cannot be met any other way. RAG fits most business use cases because your data changes daily and retraining is not practical. Fine tuning fits stable domains with strong data volume, and it can cut inference costs by letting a smaller model do the work. Production systems usually combine approaches, and agents add tool use on top. Our guides on RAG vs fine tuning and fine tuning vs prompt engineering walk through the decision in detail.
How to Choose a Generative AI Development Company
Judge production evidence, not demo quality. IDC and Lenovo research found 88% of AI proofs of concept never reach widescale deployment, so the differentiator is a partner who has taken systems past the pilot stage. Five checks that separate production teams from demo teams.
- Shipped systems with metrics. Named case studies with numbers, not logos and adjectives.
- Evaluation discipline. Golden test sets and regression runs on every prompt or model change.
- Cost engineering. Per request budgets, caching, and multi model routing designed in from the start.
- Security posture. Certified information security management, private endpoints for regulated data, and a clear data governance plan.
- An exit you would accept. Source code, prompts, evals, and documentation handed over, running in cloud accounts you own.
Our guide on how to choose an AI development company includes a scoring matrix. For adjacent needs, see AI development, agentic AI, and conversational AI.

Ready to Add Generative AI to Your Product? Start With a Proof of Concept.
Talk to an ExpertGenerative AI — Frequently Asked Questions
Generative AI development is the practice of building production systems on top of foundation models (GPT-5, Claude Fable 5, Gemini 2.5, Llama 4) that can generate text, images, code, or audio. Traditional AI focused on prediction and classification; generative AI produces new content grounded in your data via retrieval augmented generation (RAG), fine tuning, and prompt engineering.
Generative AI Insights
View all blogs



Let's Build The Next Big Thing
Fill in the form or schedule a meeting to map out a path to success.
Prefer to book directly?
🗓️ Schedule on Calendly →Or email us:
✉️sales@unicoconnect.com