CI/CD for AI Applications: What Changes in 2026

Saurav Jagdale
Technical Lead, Unico Connect
In this article
- Quick Answer
- Key Takeaways
- Why Traditional CI/CD Breaks for AI Applications
- Layer 1: Replace Unit Tests With Evaluation Pipelines
- Layer 2: Version Prompts and Models as First-Class Artifacts
- Layer 3: AI-Native Monitoring Goes Beyond Uptime
- Layer 4: Canary Rollouts for Behavioural Changes
- The Comparison: Traditional vs. AI-Native CI/CD
- EU AI Act Compliance and Audit Logging
- What We Use in Practice
- Frequently Asked Questions
Quick Answer
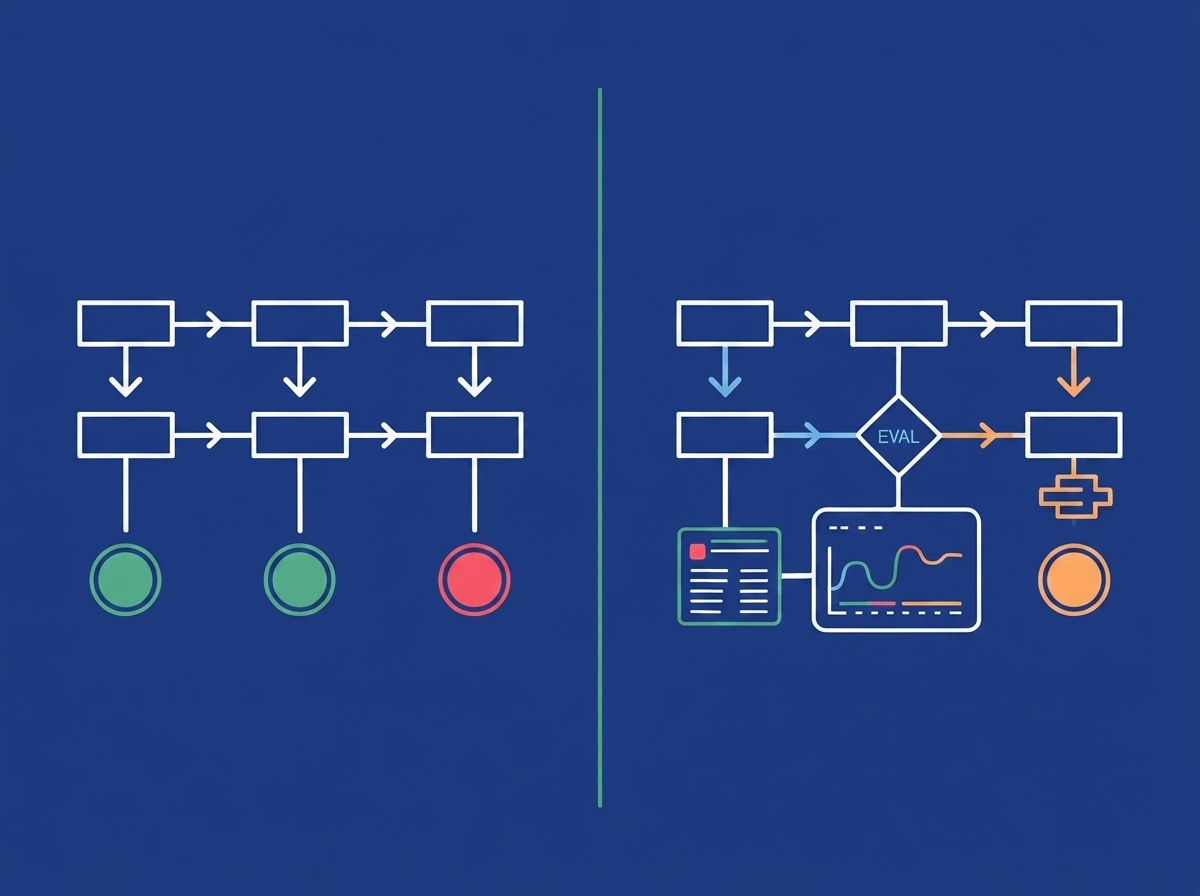
Traditional CI/CD pipelines assume deterministic code: the same input always produces the same output. AI agents do not work that way. When the system you are deploying IS an AI agent, you need to rethink testing (from unit tests to LLM evaluations), monitoring (from uptime to behavioural drift), versioning (prompts and models, not just code), and deployment strategy (canary rollouts that catch behavioural regressions, not just crashes).
Key Takeaways
- Unit tests validate scaffolding code, not AI behaviour — you need a separate evaluation layer with golden test sets
- Prompt versioning and model versioning are distinct from code versioning — both require the same change management discipline
- Production AI monitoring tracks: latency P95, token cost per request, hallucination rate, and fallback trigger frequency
- Canary rollouts for AI agents catch behavioural regressions, not just technical failures
- The EU AI Act (full enforcement 2026) requires audit trails for certain AI decisions, which changes logging architecture
When we started deploying AI agents for production clients in 2024, we used the same CI/CD setup we used for traditional SaaS products. GitHub Actions for orchestration, Docker for containerisation, standard unit and integration tests. It worked well enough for the scaffolding code. But the CI/CD pipeline told us nothing about whether the AI was behaving correctly.
Why Traditional CI/CD Breaks for AI Applications
Traditional CI/CD is designed for deterministic systems. Given input X, the function always returns output Y. LLM outputs are not deterministic. Your unit tests pass green and the AI is still wrong on 15% of edge cases. The second problem is versioning — you have three distinct things to version: application code, prompts, and the underlying model. The third problem is monitoring. Traditional APM tools track latency and error rates. They do not tell you whether the AI is being helpful and accurate.
Layer 1: Replace Unit Tests With Evaluation Pipelines
For AI applications, the test suite has two tiers:
Tier 1: Deterministic tests for scaffolding code. API routing, auth, DB operations — standard unit and integration tests apply. These run fast (under 2 minutes) and block deployment if any fail.
Tier 2: LLM evaluations for AI behaviour. A golden test set of 50-200 representative inputs with expected outputs or acceptable output criteria. An evaluation runner that scores output against expected criteria. A minimum threshold (we use 90% pass rate) before deployment. LangSmith serves as the evaluation orchestration layer. Golden set runs typically complete in 3-8 minutes and cost $1-5.
Layer 2: Version Prompts and Models as First-Class Artifacts
A prompt is not configuration. It is code. Current practice: prompts live in version control alongside application code. Every prompt change goes through a PR with a description of the intended behavioural change. Prompt changes trigger evaluation runs automatically. Each deployment is tagged with application code version, prompt version, and model version.
Layer 3: AI-Native Monitoring Goes Beyond Uptime
Technical health metrics: API response time P50/P95/P99, token consumption per request, error rates, resource utilisation.
Behavioural health metrics: Hallucination rate (via LLM-as-judge on sampled production traffic), fallback trigger rate, task completion rate, confidence score distribution, semantic drift. Behavioural metrics are tracked in Grafana. LangSmith captures full LLM traces. Alerts trigger on fallback rate above 12%, token cost 30% above baseline, and LLM-as-judge quality below 87%.
Layer 4: Canary Rollouts for Behavioural Changes
For an AI agent, a new deployment can be technically healthy while behaviourally regressed. The AI canary process: deploy to 5% of traffic, run behavioural health monitoring for 24-48 hours, compare fallback trigger rate and task completion rate against baseline. Promote to 100% only if behavioural metrics are within 5% of baseline.
The Comparison: Traditional vs. AI-Native CI/CD
| Dimension | Traditional CI/CD | AI-Native CI/CD |
|---|---|---|
| What you test | Function outputs, API responses, DB queries | Code behaviour + LLM output quality (separate layers) |
| What "passing" means | Zero test failures | Zero test failures AND eval score above threshold |
| What you version | Application code | Application code + prompts + model version (all three) |
| Deployment gate | Tests pass + linting clean | Tests pass + eval suite passes + code review on prompt changes |
| Production monitoring | Uptime, latency, error rate | Uptime + behavioural metrics: hallucination rate, fallback rate, completion rate |
| Canary success criteria | No errors, normal latency | No errors + behavioural metrics match baseline within threshold |
| Rollback trigger | Error rate spike | Error rate spike OR behavioural regression |
| Compliance logging | Request/response logs | Full LLM trace: prompt, completion, token count, confidence, model version |
EU AI Act Compliance and Audit Logging
For clients in the EU, the EU AI Act's full requirements are in effect as of August 2026. High-risk AI systems must maintain audit logs of every AI decision with sufficient context to reconstruct and review it, technical documentation of the model and training data, and human oversight mechanisms. For German manufacturing clients, Singapore FinTech clients (MAS AI governance), and US healthcare clients (HIPAA), the specific logging fields differ — but the principle is the same: your CI/CD pipeline must produce traceable records of AI decision-making.
What We Use in Practice
| Function | Tool | Notes |
|---|---|---|
| CI orchestration | GitHub Actions | Standard pipelines for code + eval runner |
| Containerisation | Docker + Kubernetes (AWS EKS) | Same as traditional; no change needed |
| LLM evaluation | LangSmith | Trace capture, eval runs, golden set management |
| Semantic evaluation | Custom Python (Ragas for RAG) | For RAG quality metrics |
| Monitoring | Prometheus + Grafana | Custom dashboards for behavioural metrics |
| Alerting | PagerDuty via Grafana | Thresholds on behavioural + technical metrics |
| Deployment | AWS CodeDeploy (blue/green + canary) | Extended behavioural health check period |
For more on production AI agent architecture at the application layer, see the MCP in production guide. The AI agent development cost breakdown includes realistic ranges for DevOps setup in AI projects. For cloud infrastructure and DevOps work on AI applications in regulated markets, logging architecture must be designed before the first deployment.
Frequently Asked Questions
Do I need a completely separate CI/CD pipeline for AI applications?
No — the existing pipeline remains but gains two new layers: an evaluation suite for LLM behaviour and AI-specific monitoring. The underlying CI/CD toolchain (GitHub Actions, Docker, Kubernetes) stays the same.
How do I test LLM output quality in CI without it being too slow or expensive?
Run evaluations against a golden test set of 50-100 representative cases, not the full production traffic corpus. Golden set evaluation runs typically complete in 3-8 minutes. Cost per run is $1-5 for most projects.
What happens when the LLM provider updates the underlying model?
Pin your model to a specific version in your configuration. When a new model version is available, run your full evaluation suite against it before upgrading. Some model updates improve average performance while degrading on specific input categories.
How do prompt changes get reviewed in a team environment?
Treat prompts as code. All prompt changes go through pull request review with a description of the intended behavioural change. The CI pipeline runs the evaluation suite on the proposed prompt change and fails the build if the eval score drops below threshold.
What is the minimum monitoring setup for a production AI agent?
At minimum: log every LLM request with timestamp, model version, prompt version, token count, and latency. Track fallback trigger rate, task completion rate, and token cost per session. Set up alerting when fallback rate exceeds 10-15%.
Does this apply to AI features embedded in traditional apps, not just standalone AI agents?
Yes. Any application component that calls an LLM and uses the output for a user-facing function requires AI-native evaluation and monitoring.



