Voice AI Agents in Production: Architecture and Lessons

Vasim Gujrati
Solutions Architect, AI & Platforms, Unico Connect
In this article
Quick Answer
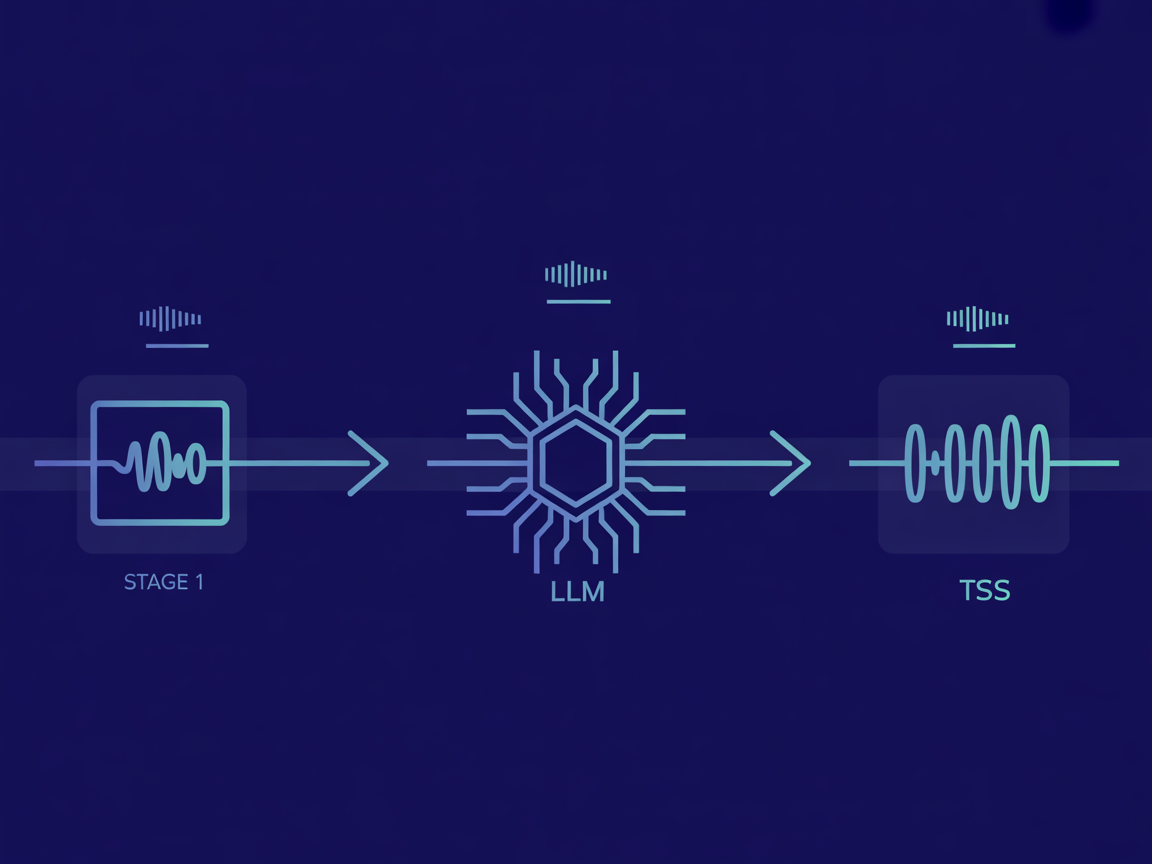
A production voice AI agent runs three integrated layers: automatic speech recognition (ASR) to transcribe user speech, a large language model (LLM) for reasoning and response generation, and a text-to-speech (TTS) engine to deliver the answer. Each layer adds latency. Total end-to-end response time in production typically runs 1.5 to 3 seconds. The architecture choices that reduce this — and the failure modes that break it — are what this post covers.
Key Takeaways
- The voice stack has three layers: ASR (Whisper/Deepgram), LLM (Claude/GPT-4), TTS (ElevenLabs/Azure Neural TTS)
- Streaming is mandatory for conversational feel; batch processing creates unacceptable pauses
- Voice activity detection (VAD) is the component most developers underestimate until production
- Multilingual voice agents require language detection before ASR, not after
- GDPR Article 13 and India's DPDP Act require explicit consent before any voice recording
When we built a voice-enabled ordering agent for a B2B commerce client, the demo took two days to build. The production system took ten weeks. The gap between those two timelines is everything this post is about.
The Three-Layer Voice Stack
Every voice AI agent runs on the same fundamental architecture. The implementation choices at each layer determine cost, latency, and reliability.
| Layer | Function | Tools We Use | Typical Latency |
|---|---|---|---|
| ASR (Speech Recognition) | Converts user audio to text | OpenAI Whisper, Deepgram, Google STT | 200-500ms |
| LLM (Reasoning + Response) | Generates the appropriate reply | Claude 3.5+, GPT-4o, Gemini 1.5 Pro | 400-1,500ms |
| TTS (Speech Synthesis) | Converts text response to audio | ElevenLabs, Azure Neural TTS, Google TTS | 150-400ms |
| Total end-to-end | From user stops speaking to first audio byte | 750ms - 2,400ms |
What We Built: B2B Voice Ordering Agent
The most instructive project we can share is the B2B WhatsApp voice ordering agent built for a manufacturing-sector client handling orders across India, UAE, and Singapore.
The requirement: a field sales representative sends a WhatsApp voice message to place an order in their native language (English, Hindi, or Arabic). The AI processes the order, confirms the details, and routes to the ERP. What was delivered: 60% faster order processing, 40% reduction in order entry errors, and voice ordering that works across 3 languages on mobile networks.
The 5 Architecture Decisions That Matter in Production
1. Stream Everything or Introduce Unacceptable Latency
In a non-streaming pipeline, the user speaks, the ASR transcribes the entire message, the LLM generates the entire response, and the TTS renders the entire audio before the user hears a single word. Total wait: 1.5-3 seconds minimum. In a streaming pipeline, the LLM starts generating tokens as soon as ASR has a partial transcript, and TTS starts rendering audio as soon as the first sentence is complete. The user hears a response within 800ms of stopping speaking.
2. Voice Activity Detection Determines Turn Quality
Voice activity detection (VAD) answers one question: has the user finished speaking? Most demos use a simple silence timer. In production with background noise, this fails constantly. Silero VAD running client-side classifies audio frames as speech or non-speech in real time at under 10ms per frame.
3. Language Detection Must Happen Before ASR, Not After
A common mistake: send all audio to English ASR, then try to detect the language of the resulting transcript. If the ASR model is English-optimised and the user spoke Hindi, the transcript is useless. The correct architecture: run a lightweight language identification model on the first 2 seconds of audio before routing to the appropriate ASR model.
4. Fuzzy Entity Matching for Domain-Specific Vocabularies
General-purpose ASR models struggle with product codes and domain-specific terminology. For the ordering agent, a post-ASR correction layer was built: a fuzzy matcher that compares ASR output against the product catalogue. For a 2,000-item catalogue, this runs in under 15ms and reduces order entry errors by 40%.
5. Compliance and Consent Are Architecture, Not Afterthought
Voice data is personal data under GDPR (EU), the DPDP Act (India), and PDPA (Singapore). For the B2B ordering agent: consent gate on first interaction, audit logging for every voice transaction, and audio storage on AWS Mumbai (ap-south-1) to satisfy India data residency requirements.
Tool Selection
ASR options: Deepgram Nova-2 has best latency for real-time streaming. OpenAI Whisper self-hosted is most cost-effective at scale with best multilingual support. Google STT v2 performs well on Indian English.
TTS options: ElevenLabs produces highest quality voices. Azure Neural TTS offers strong price-performance at enterprise scale. Google WaveNet is cost-effective for high-volume GCP deployments.
For more on production AI agent architecture, see the guide to building AI agents with Model Context Protocol. If evaluating a conversational AI partner, ask them to demo the specific failure modes, not just the happy path. See also: how to choose an AI development company.
Frequently Asked Questions
What is the best text-to-speech engine for production voice AI agents?
ElevenLabs produces the most natural-sounding voices and is best for customer-facing use cases where voice quality drives trust. Azure Neural TTS offers the strongest price-performance at enterprise scale. For cost-sensitive high-volume use cases, Google WaveNet is acceptable.
How do I keep voice AI agent latency under 2 seconds?
Use streaming throughout the pipeline: streaming ASR, streaming LLM token generation, and streaming TTS synthesis. Sentence-boundary detection ensures the TTS only renders complete sentences. Choose lower-latency LLM variants (Claude Haiku, GPT-4o mini) for conversational turns.
What compliance requirements apply to voice AI agents?
Voice recordings are personal data under GDPR (EU), DPDP Act (India), PDPA (Singapore). Key requirements: explicit consent before recording, transparent disclosure of AI processing, data retention limits, and audit logging. Build consent architecture before building the agent.
Can voice AI agents handle multiple languages in one conversation?
Yes, with the right architecture. Use a language detection model on the audio stream before routing to ASR. For code-switching, multilingual ASR models like Whisper large-v3 handle this better than routing to separate single-language models.
What is the difference between a voice chatbot and a voice AI agent?
A voice chatbot follows a scripted decision tree. A voice AI agent reasons: it understands intent, retrieves relevant information, makes decisions within defined parameters, and handles unexpected inputs with contextually appropriate responses.
How do I measure whether a voice AI agent is actually working?
Track task completion rate, fallback trigger rate (escalations to human), ASR confidence distribution, and user correction rate. Latency metrics tell you the system is fast; completion rate tells you it is actually useful.



